Section:
New Results
Person Re-identification in Real-World Surveillance Systems
Participants :
Furqan Mohammad Khan, François Brémond.
Keywords: re-identification, long term visual tracking, signature modeling
Cost of supervised metric learning
Person re-identification problem has recently received a lot of attention and the recent focus is to use supervised model training to learn cross camera appearance transformation.
In general, models are trained in a surveillance network with cameras, one for each camera pair. tracks are required to train one model with person identities.
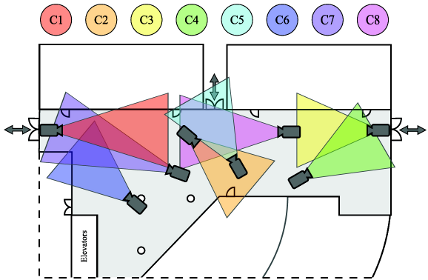
In a real-world surveillance network with non-overlapping fields of view, a person appears only in a subset of cameras (see figure 15 , courtesy of [51] ).
This puts the requirement of number of tracks to train all models at , or more precisely, . That is, to train each model with 100 people in a 10 camera network
we need 9000 tracks. For supervised training, these tracks need to be given consistent identities, and worse, have their bounding boxes marked. This is a significant burden on human
annotators for deployment in real-world. Further, the annotation cost has to be repaid at a significant fraction if only one new camera is added to the system (may be due to failure of an existing camera),
or if the lighting changes significantly (in case of outdoor surveillance).
In our opinion, this is a significant bottleneck for supervised metric learning based re-identification in real-world.
Figure
15. Camera arrangement in multi-camera surveillance scenario of SAIVT-SoftBio dataset [51]
|
|
Improved re-identification through signature modeling
Re-identification is challenging because variance is intra-class appearance in often higher than inter-class appearance due to varying lighting conditions and viewpoints, and non-uniqueness of clothing.
More importantly, in real-world when re-identification is fed by automated human detectors and trackers, significant mis-alignment or partial visibility of the person within proposed bounding box make it
difficult to extract relevant features. Our work focuses on improving signature construction from low level features for multi-shot re-identification. We explicitly model multi-modality of person appearance
using a feature mixture (corresponding publication is under review at this moment). This improves state-of-the-art re-identification performance on SAIVT-SoftBio [51] dataset and
performs equally well as state-of-the-art metric learning methods on iLIDS-VID [88] and PRID2011 [64] datasets. The performance comparison of our method with state-of-the-art
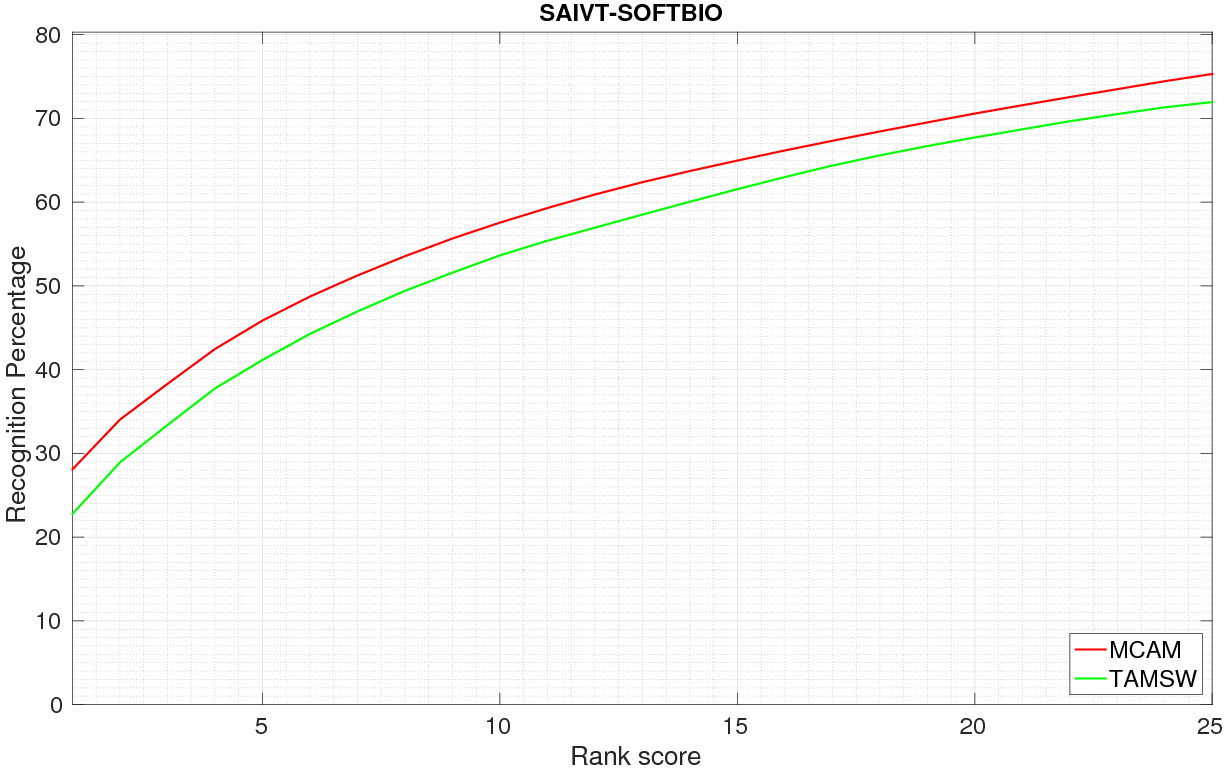
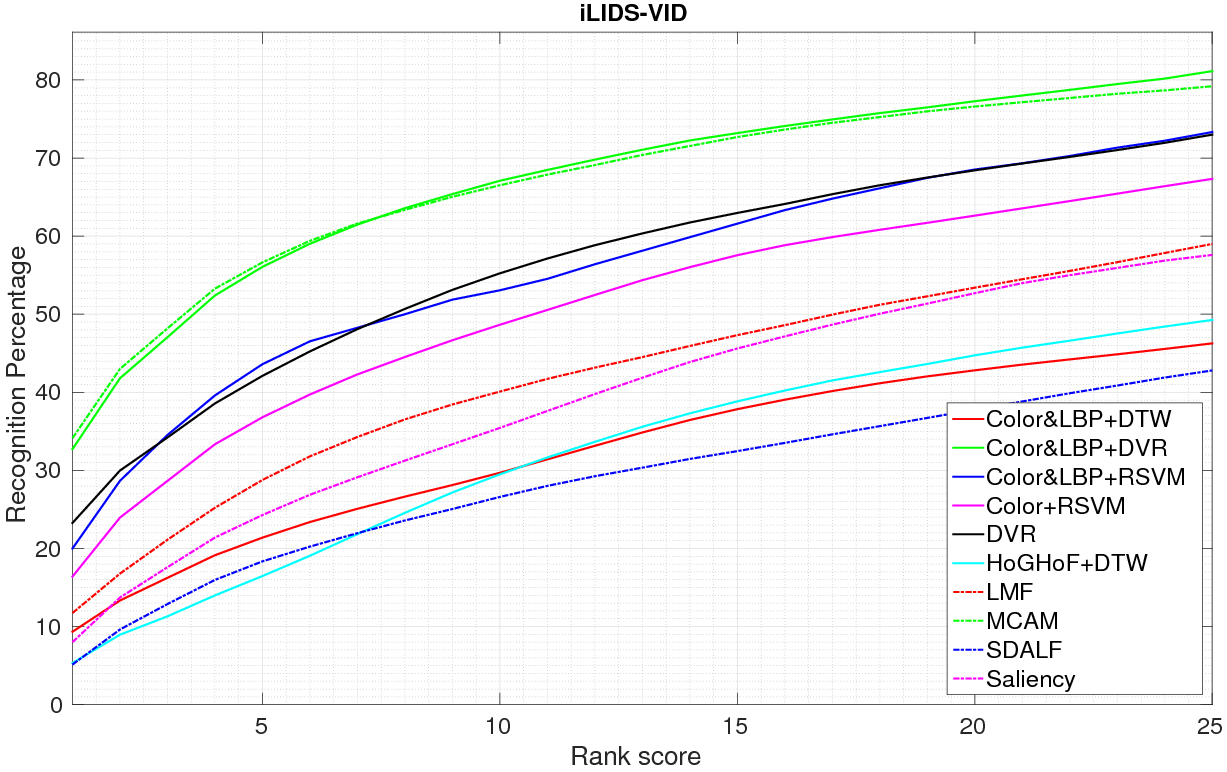
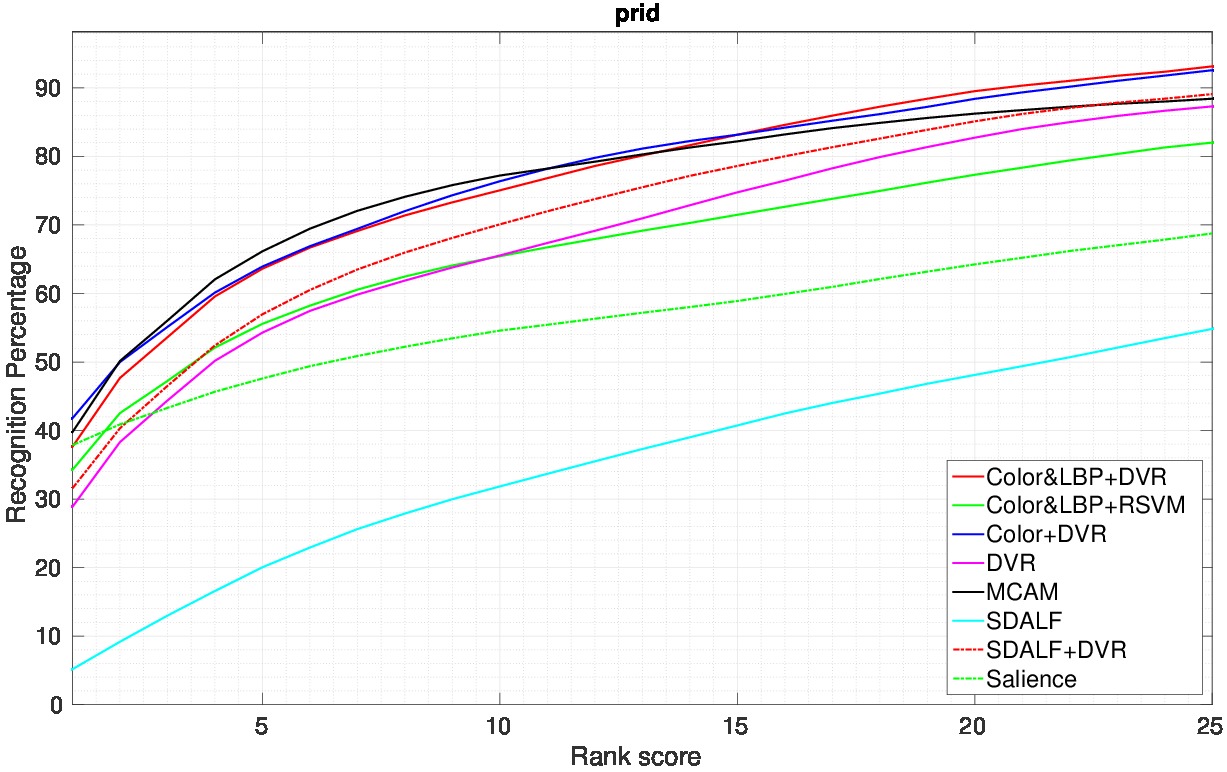
is presented using CMC in figure 16 (our results are denoted by MCAM).
Figure
16. Performance comparison of our MCAM approach using CMC curves on different datasets. Top: Comparison with TAMSW [49] on SAIVT-SoftBio dataset;
middle:Comparison with Color+RSVM [88] , Color&LBP+DTW [88] , Color&LBP+DVR [88] ,
Color&LBP+RSVM [88] , DVR [88] , HoG-HoF+DTW [88] , LMF [97] , Salience [96] , and SDALF [60] on iLIDS-VID dataset;
bottom: Comparison with Color+DVR [88] , Color&LBP+DVR [88] ,
Color&LBP+RSVM [88] , DVR [88] , Salience [96] , and SDALF [60] on PRID2011 dataset.
|
|